



Earlier this summer, I crossed the Atlantic and traveled to Madrid to give a talk at the 8th International Conference on Educational Data Mining. I presented a prototype, built by myself and my colleagues at Stanford, that stages intelligent interventions in the discussion forums of Massive Open Online Courses. Our pipeline, dubbed YouEDU, detects confusion in forum posts and recommends instructional video snippets to their presumably confused authors.

The Educational Data Mining Conference took place in Madrid this year. Pictured above the Retiro Pond in Buen Retiro Park. It has nothing to do with EDM. But I enjoyed the park so please enjoy the picture.
No, not that kind of EDM
Educational Data Mining — affectionately collapsed to EDM — might sound opaque. From the society’s website, EDM is the science and practice of
developing methods for exploring the unique and increasingly large-scale data that come from educational settings, and using those methods to better understand students, and the settings which they learn in.
Any educational setting that generates data is a candidate for EDM research. So really any educational setting is a candidate, full stop. In practice, EDM-ers often find themselves focusing their efforts on computer-mediated settings, like tutoring systems, educational games, and MOOCs, perhaps because it’s easy to instrument these systems to leave behind trails of data.
Popular methods applied to these educational settings include student modeling, affect detection, and interventions. Student models attempt to approximate the knowledge that a student possesses about a particular subject, just as a teacher might assess her student, while affect detectors classify the behavior and emotional states of students. Interventions attempt to improve the experience of students at critical times. My own work marries affect detectors with interventions in an attempt to improve MOOC discussion forums.
Making discussion forums smarter
I became interested in augmenting online education with artificial intelligence a couple of years ago, after listening to a talk at Google and speaking with Peter Norvig. That interest lay dormant for a year, until I began working as a teaching assistant for a Stanford MOOC. I spent a lot of time answering questions in the discussion forum, questions asked by thousands of students. Helping these students was fulfilling work, to be sure. But slogging through a single, unorganized stream of questions and manually identifying urgent ones wasn’t particularly fun. I would have loved an automatically organized inbox of questions.
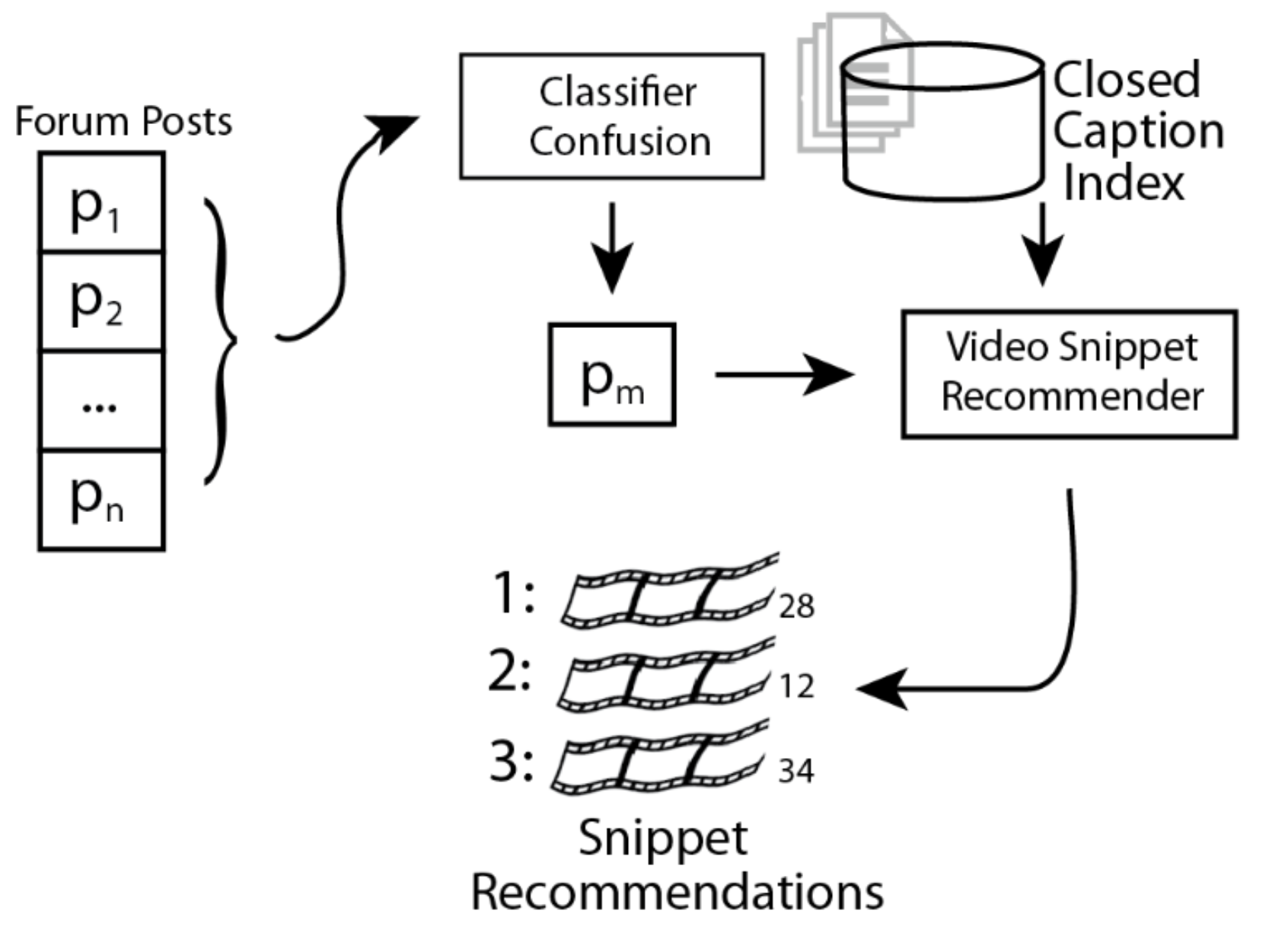
The YouEDU architecture. Posts are fed to a classifier that screens posts for confusion, and our recommender then fetches clips relevant to the confused posts.
That these discussion forums were still “dumb”, so to speak, surprised me. I reached out to the platforms team of Stanford Online Learning, who in turn sent me to Andreas Paepcke, a senior research scientist (and, I should add, an incredibly supportive and kind mentor). It turned out that I wasn’t the only one who wished for a more intelligent discussion forum. I paired up with a student of Andreas’ to tackle the problem of automatically classifying posts by the affect or sentiment they expressed.
Our initial efforts at affect detection were circumscribed by the data available to us. Machine learning tasks like ours need human-tagged data — in our case, we needed a dataset of forum posts in which each post was tagged with information about the affect expressed in it. At the time, no such dataset existed. So we created one: the Stanford MOOCPosts dataset, available to researchers upon request.
The dataset powered the rest of our work. It enabled us to build a model to predict whether or not a post expressed confusion, as well as a pipeline to recommend relevant clips from instructional videos to the author of that confused post.
YouEDU was not meant to replace teaching assistants in MOOCs. Videos are notoriously difficult to search through (they’re not indexed, like books are), and YouEDU simply helps confused students find content relevant to the topic they’re confused about. Our affect classifiers can also be used outside of YouEDU — for example, they could be used to highlight urgent posts for the instructors, or even for other students in the forum.
If you’d like to learn more about our work, you’re welcome to look at the publication, my slide deck, or the edxclassify repository.
Data mining is not nefarious
My experience at EDM was a great one. I learned lots from learned people, made lasting friends and memories, and so on. I could talk at length about interesting talks and papers — like Streeter’s mixture modeling of learning curves, or MacLellan’s slip-aware bounded logistic regression. But I won’t. You can skim the proceedings on your own time.
The EDM community is tightly knit, or at least more tightly knit that that of ACM’s Learning @ Scale, the only other education conference I’ve attended. And though no raves were attended, EDM-ers did close the conference by dancing the night away in a bar, after dining, drinking, and singing upon the roof of the Reina Victoria.
Festivities aside, a shared sense of urgency pulsed through the conference. As of late, the public has grown increasingly suspicious of those who collect and analyze data en masse. We see it in popular culture: Ex Machina, for example, with its damning rendition of a Google-like Big Brother who recklessly and dangerously abuses data, captures the sentiment well. The public’s suspicion is certainly justified, but its non-discriminating nature becomes problematic for EDM-ers. The public fears that those analyzing student data are, like Ex Machina’s tragic genius, either greedy, hoping to manipulate education in order to monetize it, or careless, liable to botch students’ education altogether. For the record, neither is true. EDM researchers are both well-intentioned and competent.
What’s an EDM-er to do? Some at the conference casually floated the idea of rebranding — for example, perhaps they should call themselves educational data scientists, not miners. Perhaps, too, they should write to legislators to convince them that their particular data mining tasks are not nefarious. In a rare example of representative government working as intended, Senator Vitter of Louisiana recently introduced a bill that threatens to cripple EDM efforts. The Student Privacy Protection Act, a proposed amendment to FERPA, would make it illegal for researchers to, among other things, assess or model psychological states, behaviors, or beliefs.
Were Vitter’s bill to go into effect as law, it would potentially wipe out the entire field of affect modeling. What’s more, the bill would ultimately harm the experience of students enrolled in online courses — as I hope YouEDU shows, students’ online learning experiences can be significantly improved by intelligent systems.
Now, that said, I understand why folks might fear a computational system that could predict behavior. I could imagine a scenario in which an educator mapped predicted affect to different curricula; students who appeared confused would be placed in a slow curricula, while those who appeared knowledgeable would be placed in a faster one. Such tracking would likely fulfill the prophecies of the predictor, creating an artificial and unfortunate gap between the “confused” and “knowledgeable” students. In this scenario, however, the predictive model isn’t inherently harmful to the student’s education. The problem instead lies with the misguided educator. Indeed, consider the following paper-and-pencil equivalent of this situation. Our educational system puts too much stock in tests, a type of predictive tool. Perform poorly on a single math test in the fifth grade and you might be placed onto a slow track, making it even less likely you’ll end up mathematically inclined. Does that mean we should ban tests outright? Probably not. It just means that we should think more carefully about the policies we design around tests. And so it is for the virtual: It is the human abuse of predictive modeling, rather than predictive modeling in and of itself, that we should guard against.
Good to see this up! Best of luck.
Hope you come to the Learning at Scale conference in Edinburgh in 2016. October 18th is submission deadline….fyi 🙂
This is very interesting, I did some similar work in the financial technology space. However, I imagine that this would be very complex and vary from subject to subject. I would be interested in learning how such studies in subject related fields were conducted and what the outcomes were.
It’s a nice experience to go through this document.