



Equipped with shiny machine learning tools, computer scientists these days are optimizing lots of previously manual tasks. The idea is that AI can make certain procedures smarter — we can capitalize on a system’s predictability and implicit structure to automate at least part of the task at hand.
For all the progress we’ve made recently in soulmate-searching pipelines and essay-grading tools, I haven’t seen too many applications of AI to computer infrastructure. AI could solve interesting infrastructure problems, particularly when it comes to distributed systems — in a reflexive sort of way, machines can and should use machine learning to learn more about themselves.
Being smart about it: The case for intelligent storage systems
Distributed systems cover a lot of ground; to stop myself from rambling too much, I’ll focus on distributed storage systems here. In these systems, lots of machines work together to provide a transparent storage solution to some number of clients. Different machines often see different workloads — for example, some machines might store particularly hot (i.e., frequently accessed) data, while others might be home to colder data. The variability in workloads matters because particular workloads play better with particular types of storage media.
Manually optimizing for these workloads isn’t feasible. There are just too many files and independent workloads for humans to make good, case-by-case decisions about where files should be stored.
The ideal, then, is a smart storage system. A smart system would automatically adapt to whatever workload we threw at it. By analyzing file system metadata, it would make predictions about files’ eventual usage characteristics and decide where to store them accordingly. If a file looked like it would be hot or short-lived, the smart system could cache it in RAM or flash; otherwise, it could put it on disk. Creating policies with predictive policy would not only minimize IT administrators’ work, but would also boost performance, lowering latency and increasing throughput on average.
From the past, a view into the future: Self-* storage systems
To my surprise, there doesn’t seem to be a whole lot of work in making storage systems smarter. The largest effort I came across was the self-* storage initiative, undertaken by a few faculty over at CMU back in 2003. From their white paper,
‘self-* storage systems’ [are] self-configuring, self-organizing, self-tuning, self-healing, self-managing systems of storage bricks …, each consisting of CPU(s), RAM, and a number of disks. Designing self-*-ness in from the start allows construction of high-performance, high-reliability storage infrastructures from weaker, less reliable base units …
There’s a wealth of interesting content to be found in the self-* papers. In particular, in Attribute-Based File Prediction, the authors propose ways to exploit metadata and information latent in filenames to bucket files into binary classes related to their sizes, access permissions, and lifespans.
Predictions were made using decision trees, which were constructed using the ID3 algorithm. With the root node corresponding to the entire feature space, ID3 splits the tree into two sub-trees corresponding to the feature that seems like the best predictor (the metric used here is typically information gain, but the self-* project used the chi-squared statistic). The algorithm then recursively builds a tree whose leaf nodes correspond to classes. As an aside, it turns out that ID3 tends to overfit training data — these lecture notes discuss ways to prune decision trees in an attempt to increase their predictive power.
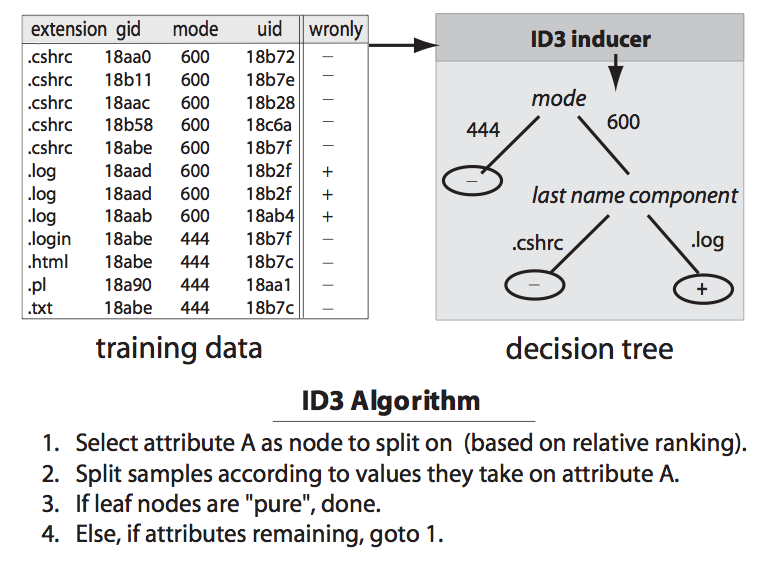
Diagram from “File Classification in Self-* Storage Systems”, by Ganger, et. al.
The features used were coarse. For example, files’ basenames were broken into three chunks: prefixes (characters preceding the first period), extensions (characters preceding the last period), and middles (everything in between); directories were disregarded. These simple heuristics proved fairly effective; prediction accuracy didn’t fall below 70 percent.
It’s not clear how a decision tree trained using these same features would perform if more granular predictions were desired, or if the observed filenames were less structured (what if they lacked delimiters?). I could imagine a much richer feature set for filenames; possible features might include the number of directories, the ratio of numbers to characters, TTLs, etc.
From research to reality: Picking up where self-* left off
The self-* project was an ambitious one — the researchers planned to launch a large scale implementation of it called Ursa Major, which would offer 100s of terabytes of automatically tuned storage to CMU researchers.
I recently corresponded with CMU professor Greg Ganger, who led the self-* project. It turns out that Ursa Major never fully materialized, though significant and practical progress in smart storage systems was made nonetheless. That the self-* project lives no longer doesn’t mean that idea of smart storage systems should die, too. The onus lies with us to pick up the torch, and to continue where the folks at CMU left off.